AWS Amplify Gen 2 でカスタムクレームを使ってマルチテナントのデータ分離を構成してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
いわさです。
先日、Amplify のサインアップ画面を変更し、ユーザーごとの任意のカスタム属性を登録出来るようにしました。
マルチテナントでのテナント ID を想定したものです。

上記は Amplify Auth を使ったカスタマイズですが、本日は Amplify Data でこのカスタム属性を使ってテナントごとにアクセスするデータの分離を行ってみます。
Amplify Data のデータ分離
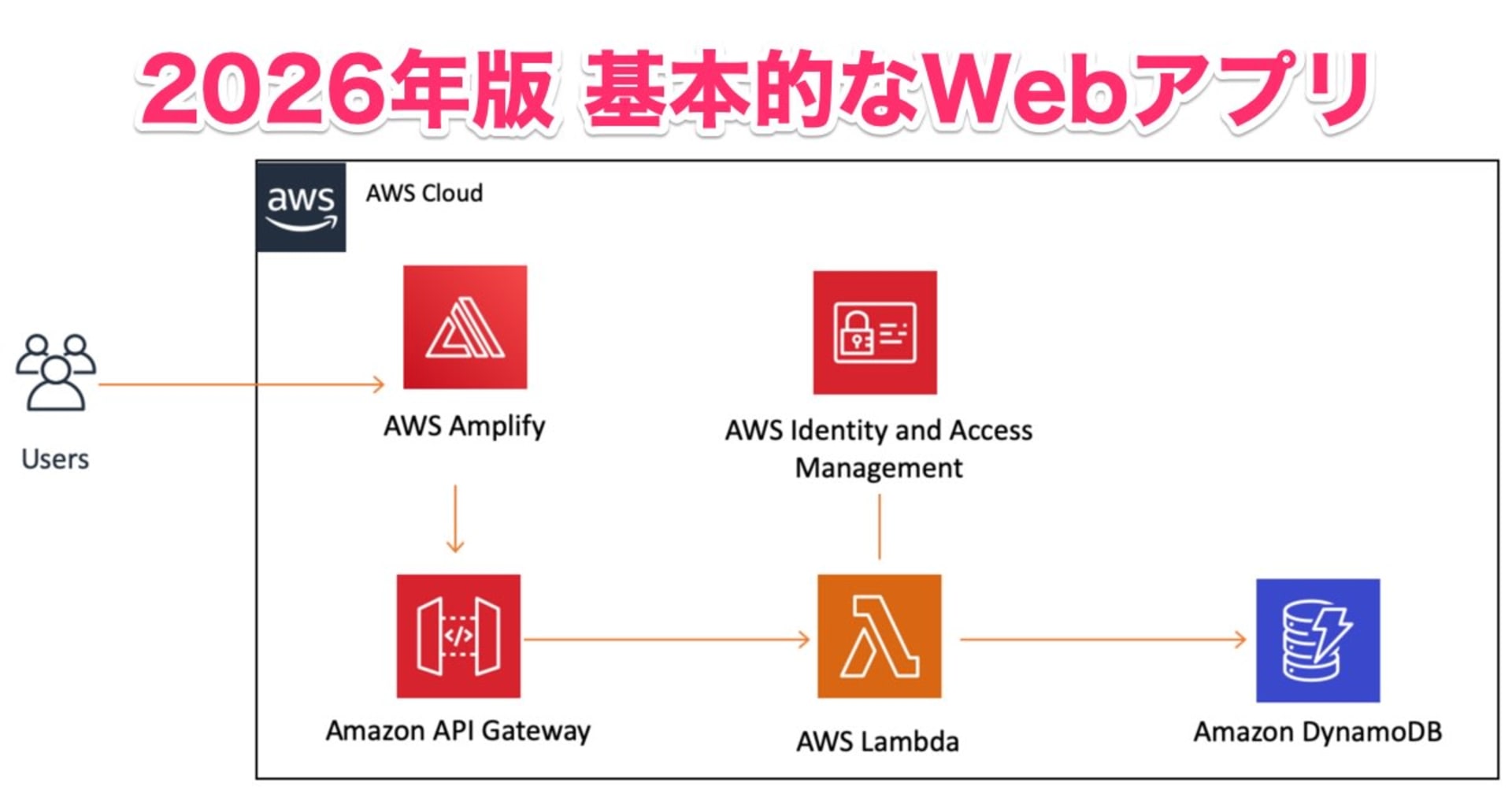
まずおさらいですが、Amplify Data を使うとデータストアに DynamoDB を使った AppSync が構成されます。
DynamoDB の項目内に識別情報が保存されつつ、AppSync のリゾルバでフィルター処理されることでユーザーがアクセス可能な情報が制限されています。
デフォルトだとトークンのsubとusernameを使った識別子が使われます。
このあたりにカスタム属性の要素を設定することで実現出来そうです。試してみましょう。
identityClaim してみる
次の公式ドキュメントで触れられていますが、カスタム属性を使う場合はidentityClaimあるいはgroupClaimを使うことが出来ます。
早速指定してみました。
import { type ClientSchema, a, defineData } from "@aws-amplify/backend";
const schema = a.schema({
Hoge: a
.model({
HogeContent: a.string(),
HogeNum: a.integer()
})
.authorization((allow) => [allow.owner().identityClaim('custom:tenant_id')])
});
:
試してみたのですが、これだけだと動作しませんでした。
理由として、Cognito ユーザープールのカスタム属性は ID トークンへのみ設定されます。
一方で AppSync クライアントで使われているのはアクセストークンであるためカスタム属性にアクセスすることが出来ませんでした。
ブラウザの開発者ツールで GraphQL を叩く際の Authorization ヘッダーを検証してみると次のようなクレーム構成です。
token_useは Cognito が設定する属性でトークンが ID トークンかアクセストークンかを識別することが出来ます。アクセストークンですね。

アクセストークンにカスタム属性を設定する
Cognito ユーザープールは少し前のアップデートでアクセストークンをカスタマイズ出来るようになりました。(要高度なセキュリティ機能の ON)
そして先日、Amplify Gen 2 でこの高度なセキュリティ機能の有効化とアクセストークンカスタマイズを行う方法を紹介しました。
上記を応用してアクセストークンにカスタム属性を設定してみましょう。
カスタマイズは Lambda トリガーで実現するのですが、リクエスト情報は以下の公式ドキュメントにまとまっていまして、どうやらevent.request.userAttributesを参照することでユーザーの属性にアクセス出来そうです。
ということで次のような Lambda 関数を用意しました。
import type { PreTokenGenerationV2TriggerHandler } from 'aws-lambda';
export const handler: PreTokenGenerationV2TriggerHandler = async (event) => {
event.response = {
claimsAndScopeOverrideDetails: {
accessTokenGeneration: {
claimsToAddOrOverride: {
"custom:tenant_id": event.request.userAttributes["custom:tenant_id"]
}
}
}
}
return event;
};
上記をデプロイして GraphQL クライアントで使われるアクセストークンを確認してみましょう。

おー、カスタム属性のテナント ID が確認出来ますね。良いですね!
データアクセスの様子
ここまでのカスタマイズで作成されるデータの様子を観察してみます。
書き込み
登録されたデータを見てみると owner にテナント ID が設定されていますね。
なお、デフォルトでownerが使われますが、ownerDefinedInでフィールドを変更することも可能です。

読み込み
テナントの異なるユーザーでそれぞれ適当なデータをいくつか登録しました。
そうすると次のようにテナント ID の異なるデータが存在する形になります。

これを異なるテナントのユーザーでアクセスしてみましょう。
次はテナントaaaのユーザーがアクセスした時です。

aaa用のデータだけが表示されていますね。
次はテナントbbbのユーザーがアクセスした時です。

こちらもbbb用のデータだけが表示されています。
さいごに
本日は AWS Amplify Gen 2 でカスタムクレームを使ってマルチテナントのデータ分離を構成してみました。
カスタム属性でデータ分離を実現することが出来ていそうです。
カスタム属性でマルチテナント処理を実装することはよく使う方法なので地味に使えるのではないでしょうか。
このカスタマイズに関係しているかまだわかっていないのですが、サインインした直後に前回表示していた情報が表示される事象が発生しているのでこれはまた別で解決したいと思います。